
라떼는말이야
[solved.ac 골드5] 1501_영어 읽기 (파이썬, 문자열, 해시맵) 본문


문제
혹시 인터넷을 하다가, 다음과 같은 식의 문장을 본 적이 있는가?
It is itnersetnig taht pepole can raed smoe grabeld wrods.
원래의 문장은 'It is interesting that people can read some garbled words'이다. 각각의 단어들은 제일 첫 문자와 제일 끝 문자를 제외하고는 순서가 뒤섞여 있다. 한 대학에서 시행한 연구 조사 결과에 따르면, (영어 단어를 아는 사람의 경우) 첫 문자와 제일 끝 문자가 일치하고, 그 사이의 문자들은 순서가 어떻게 뒤바뀌어 있더라도 읽는 데 지장이 없다고 한다.
그렇다보니, 한 단어가 여러 단어로 해석될 수도 있다. 예를 들어 abcde와 같은 단어는, abcde, abdce, acbde, acdbe, adbce, adcbe 같은 단어들로 해석될 수도 있다. 물론 각각의 단어들이 실제로 존재하는 단어(사전에 존재하는 단어)일 경우에만 의미가 있다.
영어 문장이 주어졌을 때, 그 문장을 해석하는 방법의 경우의 수를 구하는 프로그램을 작성하시오. 각각의 단어는, 첫 글자와 끝 글자가 일치하는 다른 단어(사전에 존재하는)로 해석할 수 있다. 영어 문장은 하나 이상의 단어로 이루어져 있으며, 각 단어들은 공백으로 구분되어 있다.
입력
첫째 줄에 사전에 있는 단어들의 개수 N(0 ≤ N ≤ 10,000)이 주어진다. 다음 N개의 줄에는 각 줄에 하나씩, 영어 사전에 있는 단어들이 주어진다. 각 단어의 길이는 100자를 넘지 않는다. 다음 줄에 해석할 문장의 개수 M(0 ≤ M ≤ 10,000)이 주어진다. 다음 M개의 줄에는 각 줄에 하나씩 문장이 주어진다. 각 문장의 길이는 10,000자를 넘지 않는다. 영어 단어는 알파벳 대소문자(구별됨)로만 이루어진다.
출력
M개의 줄에, 각 문장을 해석하는 경우의 수를 출력한다. 답은 32-bit signed int 범위 안에 있다고 가정하자.
예제

나의 풀이
나는 이 문제를 문자열을 해싱해서 해시 맵(파이썬에서 dict)을 사용해 풀었다.
읽을 수 있는 조건: 첫 문자와 제일 끝 문자가 일치하고, 그 사이의 문자들은 순서가 어떻게 뒤바뀌어 있더라도 읽는 데 지장이 없다
예를 들어 위 조건에 따라 abcde, abdce, acbde, acdbe, adbce, adcbe 는 abcde로 읽을 수 있기 때문에 모두 같은 해시 값을 가지도록 적절히 해싱해야 한다.
해싱 과정
1. 첫 문자와 제일 끝 문자 추출
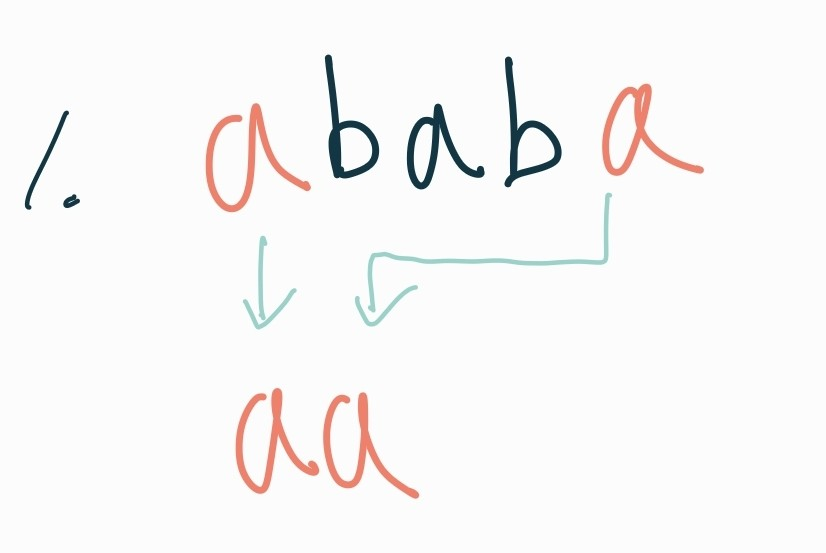
2. 첫 문자와 제일 끝 문자를 제외한 가운데 문자 정렬 후 개수 세기
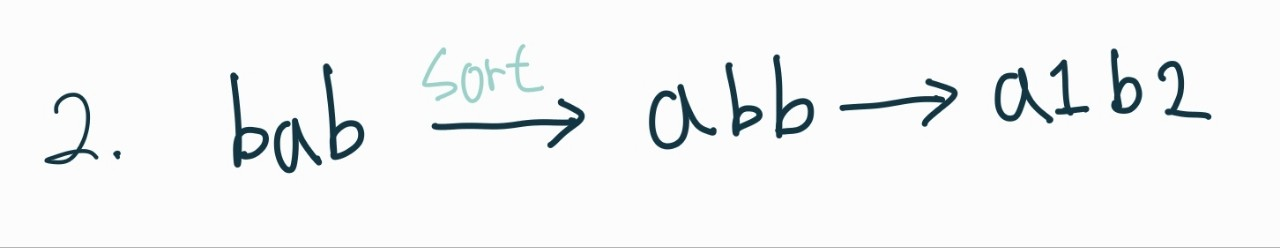
3. 합치기

위 3가지 과정을 거치면 조건이 충족하는 단어들은 모두 해석할 수 있다.
물론 위 방법은 정해진 것이 아니라 조건만 충족할 수 있으면 어떤 형태든 좋다.
주의할 점은 길이가 1인 단어는 인덱스로 접근하는 과정에서 리스트의 인덱스를 벗어날 위험이 있고, 길이가 1은 단어는 다른 단어로 읽히지 않기 때문에 그대로 키 값으로 사용한다.
코딩
가운데 문자 정렬 후 개수 세기 (파싱하기)
def parse_word(word):
last_char = "" # 마지막 문자
rtn = "" # 마지막에 리턴할 문자
count = 0 # 연속된 같은 문자의 개수
chars = sorted(word) # 문자 정렬
for char in chars:
if last_char == char: # 이전 문자와 같은 경우 개수 증가
count += 1
else: # 이전 문자와 다른 경우 rtn에 이전 문자와 개수 추가
rtn += f'{last_char}{count}'
count = 1 # 개수 1로 초기화
last_char = char # 이전 문자 최신화
else: # 반복문이 종료된 후 반드시 한 번 실행되는 부분
rtn += f'{last_char}{count}' # 마지막 문자까지 rtn에 추가
return rtn[1:] # 맨 처음에 0이 추가되므로 제거. 사실 슬라이싱 안 해도 되긴 함첫 문자와 제일 끝 문자 뒤에 파싱한 문자 합쳐서 해싱하기
def hashing_word(word):
if len(word) == 1: return word # 단어 길이가 1이면 그 자체가 해시 값
return word[0] + word[-1] + parse_word(word[1:-1]) # 첫 문자 + 끝 문자 + 파싱된 단어
사전에 단어 (해시로) 입력
dictionary = {}
for _ in range(int(input())):
key = hashing_word(input()) # 입력한 단어 해싱
if key in dictionary.keys():
dictionary[key] += 1 # 사전에 있으면 개수 추가
else:
dictionary[key] = 1 # 사전에 없으면 1로 초기화문장을 해석할 수 있는 경우의 수 구하기
for _ in range(int(input())):
sentence = input().split() # 공백을 기준으로 문장 분리
answer = 1
for s in sentence:
key = hashing_word(s) # 단어 해싱
if key in dictionary.keys():
answer *= dictionary[key] # 읽을 수 있는 경우의 수만큼 곱해준다.
else: # 사전에 없는 단어면 해당 문장은 읽을 수 없다
answer = 0 # answer에 0을 저장한 후 종료
break
print(answer) # answer 출력
전체 코드
def parse_word(word):
last_char = ''
rtn = ""
count = 0
chars = sorted(word)
for char in chars:
if last_char == char:
count += 1
else:
rtn += f'{last_char}{count}'
count = 1
last_char = char
else:
rtn += f'{last_char}{count}'
return rtn[1:]
def hashing_word(word):
if len(word) == 1: return word
return word[0] + word[-1] + parse_word(word[1:-1])
dictionary = {}
for _ in range(int(input())):
key = hashing_word(input())
if key in dictionary.keys():
dictionary[key] += 1
else:
dictionary[key] = 1
for _ in range(int(input())):
sentence = input().split()
answer = 1
for s in sentence:
key = hashing_word(s)
if key in dictionary.keys():
answer *= dictionary[key]
else:
answer = 0
break
print(answer)

'알고리즘 > 코딩 테스트' 카테고리의 다른 글
| [solved.ac 실버1] 1553_도미노 찾기 (파이썬, 백트래킹) (0) | 2022.05.13 |
|---|---|
| [프로그래머스 lv3] 표 편집 (파이썬, 문자열, LinkedList) (0) | 2022.05.06 |
| [프로그래머스 lv2] 배달 (파이썬, 최단 거리 탐색, 다익스트라) (0) | 2022.05.05 |
| [프로그래머스 lv2] 주차 요금 계산 (파이썬, 문자열, 구현) (0) | 2022.05.04 |
| [solved.ac 실버2] 1058_친구 (파이썬, 브루트포스, 그래프) (0) | 2022.04.17 |
| [solved.ac 실버1] 16918_봄버맨 (파이썬, 그래프) (2) | 2022.04.15 |
| [solved.ac 골드4] 1229_육각수 (파이썬, DP) (0) | 2022.04.15 |
| [solved.ac 실버2] 1890_점프 (파이썬, DP) (0) | 2022.04.13 |



